人工智慧學校經理人班02|統計與資料分析

統計學與機器學習的本質區別
統計學完全基於機率空間,所以又稱為機率統計學。
「如果能夠決定所觀察現象的機率分佈的參數,就可以了解所觀察現象的本質。」(Karl Pearson,1857–1936)
這是現代統計學之父所說的一段話,也點出了統計學的本質,機率分佈在統計中扮演著相當重要的角色。只要了解數據的分佈,就能描述觀察現象的各種特徵與樣貌;如果想知道母體的變異數,可以從樣本的變異數來描述、推論,只要知道機率分佈就可以辦到。
機器學習是基於統計學習理論,而統計學習理論同樣建構在機率空間上,興起於1960年代,是對於傳統統計學的擴展。而傳統統計學也同樣在發展新的技術,近代統計學也已經和以往有很大不同的樣貌了。統計與機器學習,可以看做少林與武當的關係;沒有統計學,可能就沒有機器學習的存在,但會不會發展出另一種機器學習?不知道,也無法印證。
統計雖然不是從事人工智慧的必要條件,但要在人工智慧有所突破絕對需要一定程度的統計基礎。因為「機率」是描述這個世界的基礎,而統計在於瞭解「分佈」而有了描述的標準。而標準則是讓機器學習的必要條件。
就目前的發展來看,如果你想建構一個精確的預測模型,比如說股價、房價或是疾病流行的發展,機器學習可能會是比較好的選擇。但如果是想了解數據之間的關聯或由數據來推論,統計模型會是更好的選擇。
不過講師也提到,相信在未來統計在機器學習的發展中必定可以扮演重要的角色與貢獻一己之力;身為統計人,我也同樣期待著這一天到來。
以一個線性迴歸的案例來說明統計與機器學習的差異
講師以一個簡單的案例,說明統計與機器學習是如何看待線性迴歸這件事?
在機器學習中,可以透過訓練一個基於誤差平方和最小的線性迴歸模型,來找出最佳的一條線來預測未來的數據。在統計中一樣可以找到這樣的一條線,同樣也會使得誤差平方和為最小,但是為了描述數據與結果變數之間的關聯性,而不是在對未來做預測。
簡單來說,迴歸之於統計是一個推論過程,而之於機器學習則是一個預測過程。對於機器學習來說,一定可以找出這一條線的存在,但你說這條線有多好?很抱歉,你得給我幾筆測試數據,我才能告訴你結果。如果結果不好,我可能會告訴你再給我多一些資料重新訓練這個模型。
但在統計的角度來說,可以再進一步檢定β1是否為零?也就是數據與結果變數是否存在關係?如果檢定結果無法拒絕β1為零的假設,那麼就表示這個線性迴歸模型根本就不存在,不應該用線性迴歸來解釋數據間的關係(也不該用來預測),但有沒有可能存在其他的關係,則可以進一步檢視分析。
在機器學習中只在乎這個模型能不能用,而不在意如何去解釋其中的機制;但在統計中更在意的是數據之間的關聯性與重要性,以及如何透過模型去詮釋這些數據。當然,統計也可以做為預測,但這不是其主要目的。
相關係數為零就是不相關?
當然不是。只能說是沒有「線性」相關,但可能有其他關聯性,比如說二次相關、部分相關等等。
相關係數,或正式來說的Pearson’s corr其實只是診斷「線性相關」的一種統計量。相關係數為零,只能說不存在「線性相關」而不能說是沒有相關。
在統計上有不同的統計量可以診斷關聯性,像是Pearson corr(看距離)、Spearman rank corr(看排名)、Kendall’s tau(看趨勢);儘管如此,「不要只看數據,要搭配圖形」在統計上是很重要的一點。
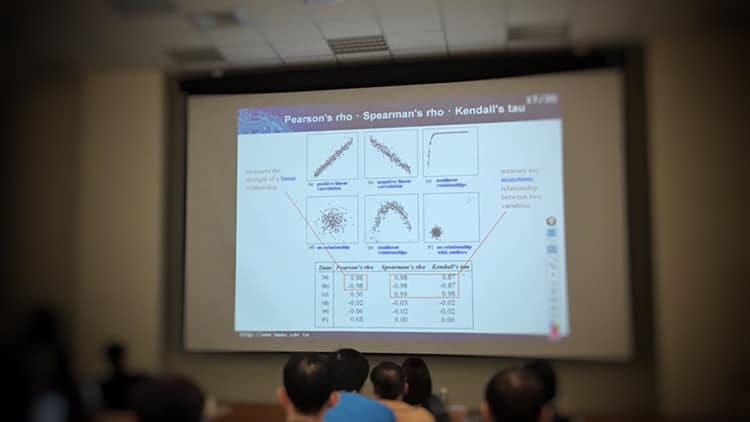
像這六種圖形都存在著某種關聯性,但未必能用相關統計量呈現出來,更別說想用我們熟知的「相關係數」來解釋所有的關聯性了。
貝氏統計是一門統計學派,也是機器學習所採用的統計基礎
貝氏統計是統計的門派之一,我們熟知的統計,或者說基礎統計講的是次數統計。兩者最主要的差異在於貝氏中的參數也有其分佈,而不像次數統計中是固定的常數。

比如,我們說有一個觀察母體是服從某一平均數與變異數的常態分佈,通常這個平均數與變異數指的一個固定的數值。但在貝氏中,平均數是一個變動的值,可能是一個常態分佈、也可能是其他分佈。
當更清楚參數的分佈時,我們對於觀察母體的分佈就有更精確的掌握。白話地說,我們掌握更多線索時,對於一件事的評估可能會變動,而且更為精確,因為我們納入了更多訊息。
而機器學習則採用了貝氏統計,做為改善機率精確度的基礎之一。
課程中帶給我的五點啟發
一、統計是與時俱進的
相較於十多年前在校所學,多了很多新的統計技術,這是為了因應各種新的資料型態與限制;但本質概念仍是相同的。
比如說遺失值的處理,過去可能是視為無效資料或是以平均值代入,但如此可能會失去太多資料或使資料結構改變而失真。現在已經有很多補值的技術,像是影像處理或是馬良神筆都是一種補值的應用。別再以為拒答,就無法將資料估算出來喔!當然,目前還是有技術上的限制。
二、思維比技術更為重要
在一天的課程中要完全掌握統計這門學科很難,對於零基礎更是不可能。但試著去瞭解為什麼會有這門技術?運用的場景、限制與發展的路徑還是有機會,也挺有趣的。技術是實踐的基礎,思維是突破的關鍵。
像是最後提到的如何利用統計檢定與分析來驗證川普的推特是不是自己發的?方法我們統計人可能都會,但就是不會想到這樣運用。
三、好名稱很重要
一項技術能否普及與吸引大眾,有時名稱也扮演著重要的角色。
比如說:資料挖礦(data mining) 現在叫大數據(big data);而深度學習(deep learning) 在統計中可能稱為多階層廣義線性回歸模式,聽起來就讓人興趣缺缺。這點也是為何統計長期難以推廣的主要原因。
四、視覺化很重要
看到資料的長相,決定下一步怎麼走。沒有視覺化,可能會漏掉資料隱含的訊息而誤判。例如圖中的十三組資料算出來的平均值與標準差都一樣,但資料的關聯與長相完全不同。
五、峰終定律:在對的時間用對力氣
枯燥又緊湊的主題怎麼講?運用峰終定律,掌握開場、亮點與結尾(今年有上過我課的應該都聽過),講師最後以「川普的推特是誰發的」為案例,說明統計如何分析與推論,果然讓大家眼睛為之一亮,獲得滿堂彩。
結語:對正確的問題有個近似的答案,勝過對錯的問題有精確的答案

「對正確的問題有個近似的答案,勝過對錯的問題有精確的答案。」(John Tukey,1915–2000)
我很喜歡的一句話,是統計界的畢卡索講的。主修化學,卻轉而唸數學博士,然後在二戰期間投入實務統計研究火砲控制問題,你說這個人是不是特立獨行?發明了快速傅立葉轉換,也對探索性資料分析有極大貢獻,改變了近代統計的面貌。
在工作上、生活中,問對問題永遠比找到標準答案來得重要。你會發現許多大師都說過類似的道理,像是愛因斯坦。然而,太多人執著於在錯誤的問題上找到精確的答案,甚至做為攻擊對方的手段,一點意義也沒有。
文章同步發佈於 Medium-職人簡報與商業思維

